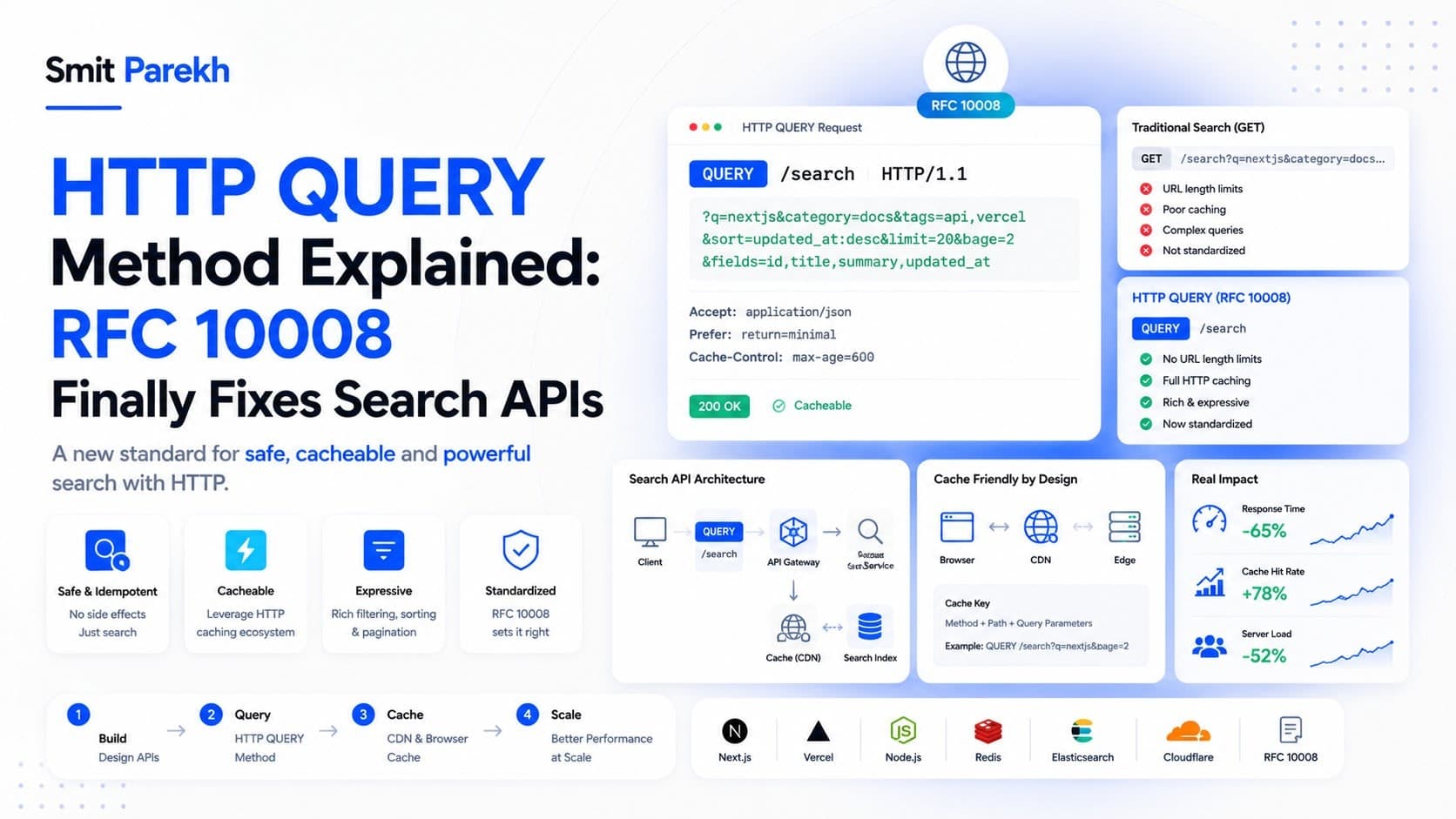
- *QUERY = safe, idempotent, cacheable requests that carry a body**, standardi
HTTP does not change often. For basically our entire careers, the spec has shipped with the same handful of verbs we all know: GET to fetch data, POST to create or send data, PUT to replace or update a resource, and DELETE to remove one. So when the IETF publishes a brand-new method, it is worth paying attention.
In June 2026, the RFC Editor published RFC 10008: The HTTP QUERY Method as a Proposed Standard. QUERY closes a gap that has existed in HTTP since the beginning — and if you have ever built a search endpoint, you have felt this gap personally.
The Problem: Search Never Had a Home
Think about what a real-world search or filtering endpoint needs to accept: sorting rules, pagination cursors, nested conditions, date ranges, arrays of IDs, maybe a full structured filter object. Every non-trivial API grows one of these endpoints eventually. And until now, every option for building it was broken in a different way.
Option 1: GET with query parameters
Semantically, GET is the right choice. You are reading data, not changing anything. GET is safe(no side effects) andidempotent (repeating it changes nothing), which means browsers, proxies, and CDNs can cache and retry it freely.
The problem is that GET puts everything in the URL. URLs have length limits — and worse, nobody knows the real limit ahead of time, because a request can pass through several uncoordinated intermediaries. RFC 9110 only recommends 8,000 octets as a floor. Push past whatever limit your stack enforces and the server throws a 414 URI Too Long.
There are other issues too:
- Structured data like nested filters is awkward and expensive to encode into a URI-safe string.
- URLs are far more likely to be logged, bookmarked, and shared than request bodies — a real concern when filters contain sensitive values.
- Every combination of query inputs becomes a separate resource, which fragments your cache.
Option 2: GET with a request body
The next logical thought: just put the query in the request body of a GET call. Technically the spec does not forbid it. In practice, GET requests with bodies are handled inconsistently across clients, proxies, servers, and firewalls. Some tools reject them outright, some silently ignore the body, and some behave differently depending on the environment. You cannot build a reliable public API on behavior that unpredictable.
Option 3: POST for searches
So the most common workaround became POST /search. POST happily carries a body, so your filters fit. But POST lies about intent. POST is meant to change state on the server, so the protocol treats it as neither safe nor idempotent. That has real consequences:
- Caches and CDNs will not cache a POST response, because they must assume it mutated something.
- Clients and proxies cannot automatically retry a failed POST, because retrying a state-changing request could cause duplicate writes.
- Tooling, monitoring, and security layers cannot tell your read-only search apart from an actual mutation.
Every REST API I have worked on eventually grew a POST /search endpoint — not because POST was right, but because nothing better existed.
Enter QUERY: GET Semantics, POST Body
RFC 10008 defines QUERY as a method that combines the useful parts of GET and POST:
- Like GET, QUERY is safe and idempotent. You are telling the server — and every proxy in between — that the request only reads data and can be repeated or retried without side effects.
- Like POST, QUERY carries a request body. Your filters live in the payload instead of being crammed into the URL.
- QUERY responses are cacheable. Crucially, the cache key is built from both the request body and its metadata, not just the URL. Two QUERY requests to the same URL with different bodies are correctly treated as different queries.
Here is what a QUERY request looks like on the wire:
QUERY /users HTTP/1.1
Host: api.example.org
Content-Type: application/json
Accept: application/json
{
"role": "admin",
"createdAfter": "2025-01-01",
"sort": [{ "field": "name", "order": "asc" }],
"page": { "size": 25, "cursor": "eyJpZCI6MTAyfQ" }
}
Compare that to the base64-encoded JSON blob jammed into a query parameter that this replaces, and the appeal is obvious. The request is readable, structured, versionable, and it keeps sensitive filter values out of access logs.
Why the Semantics Matter More Than the Body
It is tempting to summarize QUERY as "GET with a body," but the spec deliberately avoids that framing — and for good reason. The body support is the convenient part; the semantics are the valuable part.
Because QUERY is explicitly declared safe and idempotent at the protocol level:
- Intermediaries can cache responses. CDNs like Cloudflare and Akamai — whose engineers co-authored the RFC — can serve repeated queries from the edge instead of hammering your origin.
- Clients can retry automatically. A dropped connection mid-request? Retry without fear of partial state changes or duplicate writes.
- Infrastructure understands intent. Gateways, WAFs, observability tools, and rate limiters can treat reads differently from writes, because the method finally tells the truth.
None of this is possible with POST /search, no matter how well you document that the endpoint is read-only. The protocol does not know, so the ecosystem cannot help you.
Where Adoption Stands Today
QUERY reached Proposed Standard status, which is the stage where implementations begin in earnest. The state of the ecosystem as of mid-2026:
- Node.js has parsed QUERY as a method natively since early 2024, so a plain Node HTTP server can handle it today.
- Go and Rust treat HTTP methods as strings, so you can route QUERY requests right now with standard-library primitives — no new dependencies required.
- ASP.NET Core has an open proposal to add first-class support.
- OpenAPI 3.2 can document QUERY endpoints.
- Spring support is an open pull request that gained momentum the same week the RFC published.
- Browsers and
fetch()are the slower story. Adoption across browsers, proxies, and corporate firewalls with method allowlists will roll out gradually, the way these things always do.
A Sensible Migration Path
Because infrastructure support is still catching up, do not rip out your POST /search endpoints overnight. A pragmatic rollout looks like this:
- Add QUERY alongside your existing POST search endpoint. Same handler logic, two routes.
- Advertise support so capable clients can discover the newer method (the spec defines an
Accept-Querymechanism for servers to signal this). - Let clients migrate as their tooling allows. SDKs, HTTP clients, and proxies will add support at different speeds.
- Keep POST as the fallback for environments that block unknown methods.
If you are designing a greenfield internal API where you control both ends — say, a Next.js frontend talking to your own Node.js services — you can adopt QUERY much more aggressively, since you are not at the mercy of unknown intermediaries.
What This Means for API Design
For teams building APIs with complex filter payloads — search endpoints, report builders, analytics dashboards, AI-powered retrieval endpoints — QUERY is arguably the most significant addition to HTTP semantics since PATCH became widely adopted. It gives read-heavy, parameter-rich endpoints a method that is honest about what they do, and it unlocks caching and retry behavior that POST could never offer.
My prediction: within a few years, POST /search will read as a legacy idiom, the same way we now look at APIs that tunnel everything through GET with a ?method=delete parameter.
It is not every day we get a new HTTP method — the last thing most of us expected this year. But the gap was real, the fix is clean, and the spec is short and genuinely readable. If you build or consume APIs for a living, RFC 10008 is worth thirty minutes of your time.
zed in RFC 10008 (June 2026).
- GET breaks on URL length and leaks filters into logs; GET-with-body is unreliable across intermediaries; POST hides read-only intent and kills caching.
- Cache keys for QUERY are derived from the request body plus metadata, not just the URL.
- Node.js, Go, and Rust can handle QUERY today; framework and browser support is rolling out gradually.
- Adopt it incrementally: run QUERY alongside
POST /searchand let clients migrate as tooling matures.